Programming in UNIX Environment
우리가 컴퓨터를 처음 쓸 때에는 컴퓨터란 어떻게 우리 최종 사용자들이 쓰기 쉽도록 동작하는지 관심을 가지지 않는 사람이 많을 것입니다. 보통은 컴퓨터로 어떤 것을 할 수 있는지, 어떻게 할 수 있는지가 중요하죠.
컴퓨터는 어떻게 사용자들이 쓰기 쉽게 만들어져 있을까요?
사실 컴퓨터 시스템은 사용자가 쓰기 편한 것도 중요하지만, 컴퓨터 시스템을 유지보수하는 사람들이 쉽게 유지보수 하는 것도 중요합니다. 근데, 컴퓨터같이 복잡한 시스템은 시스템의 여러 부분이 서로 관련이 많기 때문에 유지보수하기 어렵죠. 그래서 컴퓨터 설계자들은 복잡한 컴퓨터 시스템을 잘게 나눕니다.
복잡한 시스템을 여러 개의 계층으로 나누고, 각 계층간의 소통하는 인터페이스를 정의하면 인터페이스 변경이 아니라면 각 계층의 유지보수는 다른 계층에 영향을 적게 받게 됩니다. 그런 이유에서 컴퓨터 시스템은 아래처럼 여러 개의 계층으로 나눠져 있습니다.
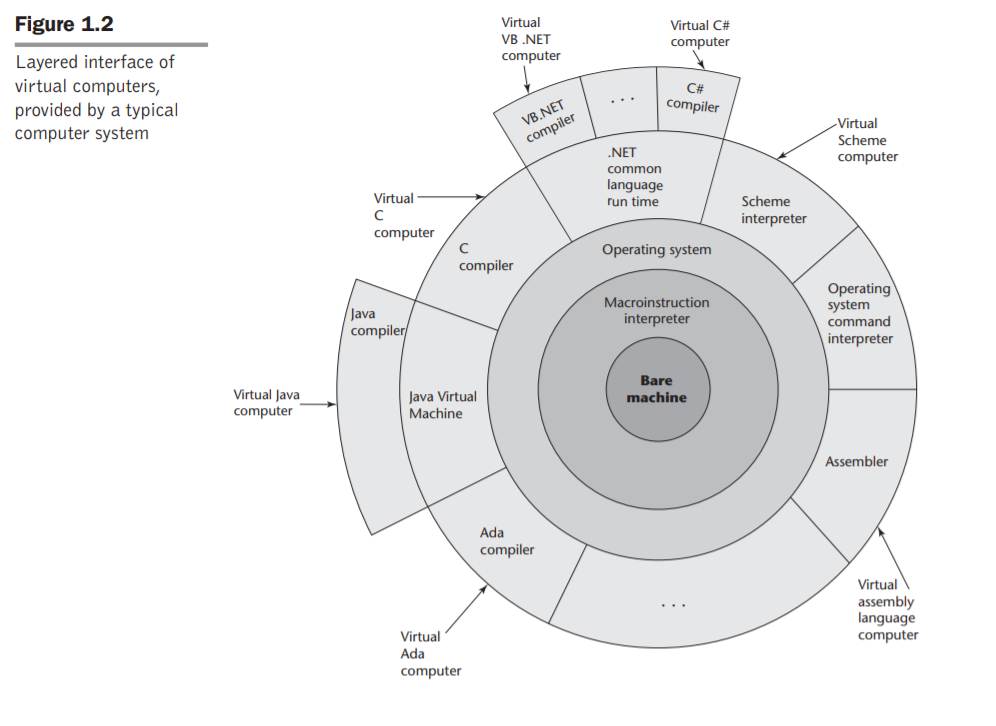
가장 바깥쪽은 우리 최종 사용자들이 사용하는 응용 프로그램이 있고, 그 안쪽은 그 프로그램을 해석/실행하는 컴파일러/인터프리터가 있습니다. 그 밑에 있는 것은 Operating System이죠. Operating System 계층은 잘 보면 계층 모두가 Operating System 하나로만 되어있습니다.
그리고.. 가장 안쪽엔 Bare machine이 있습니다. 이렇듯, 응용 프로그램이 컴퓨터의 핵심적인 계산 자원인 CPU와 Memory(그외 등등..)를 쓰려면 Operating System을 거쳐야 합니다.
UNIX_Programming 태그의 포스트 시리즈에서 얘기할 것은 Operating System 중 하나인 UNIX입니다. 특히 우리의 응용 프로그램(그림의 맨 바깥쪽 계층)이 UNIX(Operating System 계층)를 활용하려면 어떻게 프로그래밍해야 하는지에 대한 이야기입니다.
이번 포스트에서는 UNIX 시스템 전반과 사용자 식별, 파일 시스템, 입출력, 시간 처리등에 대해 간단하게 살펴보겠습니다.
UNIX Architecture
Operating System(운영체제)란 무엇일까요?
컴퓨터의 하드웨어 자원을 제어하고, 프로그램이 실행될 수 있는 환경을 제공하는 소프트웨어라고 정의할 수 있습니다. 일반적으로 이런 소프트웨어를 kernel(핵)이라고 부르는데, 커널이 비교적 작으며 실행 환경의 중심에 있기 때문입니다.
이런 커널에 대한 인터페이스는 시스템 호출(system call)이라고 부르는 소프트웨어 계층입니다. 응용 프로그램들과 다른 여러 프로그램들은 시스템 호출을 이용해서 커널을 사용합니다.
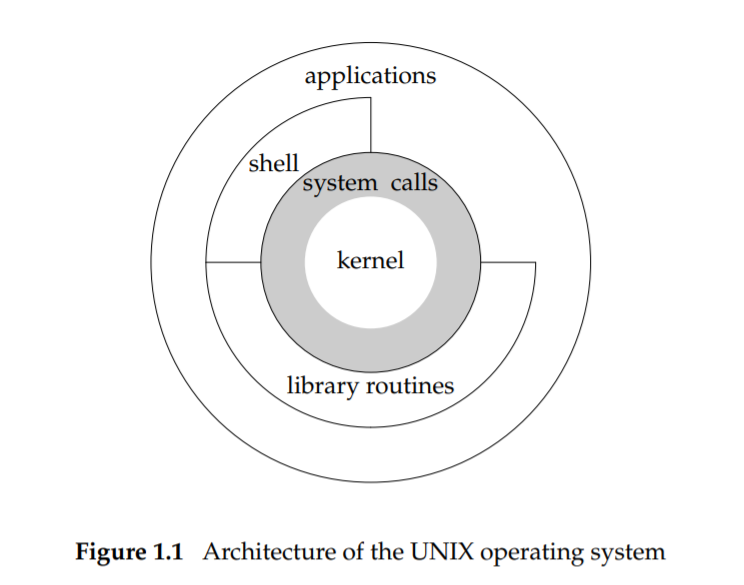
응용 프로그램과 셸 프로그램, 공용 라이브러리는 커널을 사용하기 위해 system call을 거쳐야 합니다. 공용 라이브러리는 시스템 호출을 쉽게 쓰게 해주는 인터페이스이고, 응용 프로그램은 시스템 호출과 공용 라이브러리 둘 다 활용할 수 있습니다. 셸은 다른 프로그램의 실행을 위한 인터페이스를 제공하는 특별한 응용 프로그램입니다.
Shell
UNIX 시스템 로그인이 성공하면 셸 프로그램에 명령을 입력하고 UNIX 시스템을 사용할 수 있게 됩니다. 셸은 사용자 입력을 읽어서 명령을 실행하는 명령줄 해석기(Command Line Interpreter)입니다.
아래는 자주 쓰이는 셸 프로그램을 정리한 것입니다.

UNIX 시스템은 로그인한 사용자의 셸을 패스워드 파일 해당 사용자 행의 마지막 필드에 있는 셸 프로그램으로 결정합니다.
셸에 대한 더 자세한 역사와 정보는 wiki나 다른 자료를 확인해주세요.
User Identification
Login
UNIX 운영체제를 사용하려면, 먼저 로그인을 해야 합니다.
로그인 이름(login name)과 비밀번호(password)를 입력하면 UNIX 시스템은 입력된 이름을 패스워드 파일에서 찾아보는데, 보통 /etc/passwd 파일에서 찾습니다.
해당 패스워드 파일을 확인해 볼까요?
cat /etc/passwd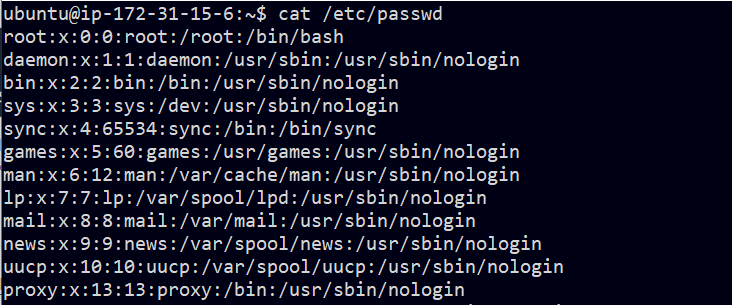
위의 결과에서 하나의 행은 :(콜론)으로 구분된 필드 7개로 구성되어 있습니다.
root:x:0:0:root:/root:/bin/bash7개의 필드는 순서대로
- 로그인 이름(
root) - 암호화된 패스워드(
x) - 사용자ID(정수,
0) - 그룹ID(정수,
0) - 주석 필드(
root) - 홈 디렉터리(
/root) - 셸 프로그램(
/bin/bash)
입니다.
위에서 암호화된 패스워드는 모두 똑같이 x로 나타나는데, 이는 개별적인 파일에 옮겨져 있어서 그렇습니다.
이 포스트 에서 이 파일들과 파일에 접근하는 함수를 몇가지 보겠습니다.
User ID
패스워드 파일에 있는 사용자 ID는 시스템이 사용자를 식별하는 숫자 값입니다. 이 값은 시스템 관리자에 의해 할당되고, 사용자 자신이 바꿀 수는 없습니다. 커널은 주어진 사용자가 특정 행동을 하는 권한을 사용자 ID를 이용해서 확인합니다.
특히 사용자 ID이 0인 사용자를 root 혹은 슈퍼사용자(superuser)라고 부릅니다.
슈퍼사용자의 패스워드 파일에서의 로그인 이름은 보통 root이며, 슈퍼사용자는 시스템의 모든 것을 마음대로 주무를 수 있습니다.
Group ID
패스워드 파일엔 사용자의 그룹 ID도 있는데, 이것 역시 시스템 관리자가 할당합니다.
보통 그룹은 사용자들을 조직화하여 권한을 부여하는데에 쓰이며, 그룹에 속한 사용자는 해당 그룹의 권한을 얻게 됩니다.
추가로, 대부분의 UNIX 시스템은 사용자가 여러 그룹에 속할 수 있게 허용합니다.
시스템은 /etc/group파일에서 해당 사용자가 멤버로 등록된 첫 16개의 그룹을 읽어서 추가 그룹 ID를 얻습니다.
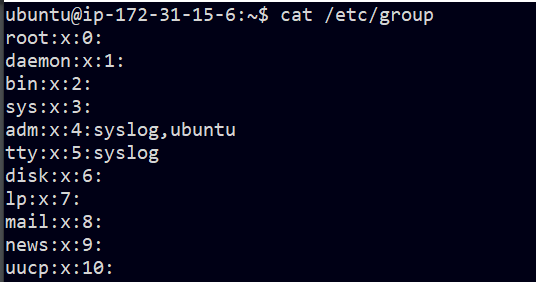
cat /etc/group 커맨드 결과
Login Name & Group Name
/etc/group파일에 보면, 그룹ID(숫자)를 그룹 이름(문자열)에 대응시키는 내용입니다.
마찬가지로 /etc/passwd파일도 사용자마다 사용자ID(숫자)와 로그인 이름(문자열)이 있습니다.
사용자와 그룹을 식별하는데에는 한가지면 충분한데, 왜 두가지 표현 방식이 있을까요?
컴퓨터에겐 숫자가, 사람에겐 문자열이 식별하기에 쉽기 때문입니다.
파일 시스템은 접근 권한 처리를 위해 파일마다 파일을 소유한 사용자의 사용자ID와 그룹ID를 함께 저장합니다. 이때 문자열로 저장하는 것은 정수로 저장하는 것보다 더 많은 디스크 공간을 차지하고, 문자열끼리의 비교는 정수 비교보다 훨씬 비쌉니다. 하지만 사람에게는 문자열이 더 알아보고 다루기 쉽습니다. 그래서 패스워드 파일과 그룹 파일은 각 ID와 함께 이름을 같이 저장하며, 파일 시스템과 여타 시스템들은 이 파일을 통해 ID와 이름을 매칭합니다.
사용자 식별과 관리에 대한 더 자세한 내용은 이 포스트 를 참고하세요.
File and Directory
File System
UNIX 파일 시스템은 디렉터리와 파일들을 트리 형태로 조직화한 것입니다.
파일 시스템의 모든 것은 root라고 부르는 디렉터리에서 시작하고, 그 이름은 한 문자짜리 /입니다.
디렉터리는 디렉터리 항목을 담은 파일입니다. 디렉터리 항목은 파일이름과 파일의 특성 등을 담고 있는 정보라고 생각하면 편합니다. 파일의 특성들로는 파일의 종류, 파일의 크기, 파일의 소유자, 파일의 접근 권한, 파일의 마지막 수정 일시 등등.. 이 있습니다.
drwxrwxr-x 8 ubuntu ubuntu 4096 Sep 29 15:31 .npmstat 함수와 fstat 함수는 한 파일의 모든 특성을 담은 정보 구조체를 돌려줍니다.
Filename
디렉터리 안에서 파일들은 모두 이름이 있습니다.
파일 이름에 사용할 수 없는 문자는 단 두 개로, 슬래시 문자(/)와 널(NULL)문자 입니다.
/는 경로 이름을 구성하는 파일 이름들을 구분하는 역할을 하고, NULL 문자는 하나의 경로 이름의 끝을 표시합니다.
하지만 보통의 시스템들은 파일 이름에 사용할 수 있는 문자를 제한하고, 보통 영문자(a-z, A-Z), 숫자(0-9), 마침표(.), 대쉬(-), 밑줄(_)로 제한됩니다.
그니까 여러분도 파일 이름 지을때 위에서 말한 글자만 쓰시고, 띄어쓰기( )는 -/_로 대체하고 특수문자(!@#$%^&*()[]{}?><>, 등등..)는 쓰지 마세요.
새 디렉터리를 만들면 자동으로 생성되는 파일 이름이 두 개가 있는데, .(현재 디렉터리)와 ..(부모 디렉터리)가 생깁니다.
또, 루트 디렉터리는 .와 ..이 같습니다.
Pathname
경로 이름(pathname)은 하나 이상의 파일 이름들이 /로 연결된 형태입니다.
/로 시작하는 경로를 절대 경로(absolute pathname)라고 하고, 그렇지 않으면 상대 경로(relative pathname)라고 부릅니다.
상대 경로이름은 현재 디렉터리에 상대적인 파일을 가리키게 됩니다.
Working Directory & Home Directory
현재 프로세스가 작업하는 디렉터리는 현재 작업 디렉터리(Current working directory/pwd)라고 부릅니다. 작업 디렉터리는 모든 상대 경로이름이 해석되는 기준으로 쓰입니다. 사용자가 로그인하면 작업 디렉터리는 사용자의 홈 디렉터리로 설정됩니다. 각 사용자의 구체적인 홈 디렉터리의 절대 경로이름은 패스워드 파일 중 현재 사용자 행에 들어있습니다.
File과 Directory에 대한 내용들은 이 포스트 에서 자세히 다루겠습니다.
Input & Output
File Descriptors
파일 서술자는 커널이 프로세스가 접근하는 파일들을 구분하기 위해 쓰는, 일반적으로 작은 양의 정수입니다. 프로세스가 이미 존재하는 파일을 열거나 새 파일을 만들면, 커널은 파일을 읽고 쓰는데 쓸 파일 서술자를 반환합니다.
Standard Input, Standard Output, Standard Error
일반적으로 프로그램이 실행되면, 모든 셸들은 표준 입력, 표준 출력, 표준 에러의 세 가지 서술자를 엽니다.
ls 같은 단순한 커맨드를 실행하면, 세 가지 모두 터미널에 연결됩니다.
대부분의 셸은 이 세 가지 서술자를 파일로 리다이렉트하는 방법을 제공합니다.
ls > file.list위에서, ls 커맨드는 표준 출력을 file.list 파일로 리다이렉트합니다.
Unbuffered I/O
버퍼링되지 않는 I/O는 open, read, write, lseek, close 같은 함수가 제공해줍니다.
이 모든 함수들은 파일 서술자를 이용합니다.
File descriptors, Std input/output/err, unbuffered I/O에 대해선 이 포스트에서 자세히 설명합니다.
Standard I/O
표준 입출력 함수들은 버퍼링 없는 입출력 함수의 버퍼링되는 인터페이스를 제공합니다.
표준 입출력을 쓰는 것은 최적의 버퍼 사이즈를 결정하는 등의 문제를 생각하지 않아도 되게 해주며, 라인 단위 입력을 처리하기 쉽게 해줍니다.
가장 일반적인 표준 입출력 함수는 printf일 겁니다.
printf를 사용하기 위해, 모든 표준 입출력 함수의 함수 프로토타입을 가지고 있는 <stdio.h> 헤더 파일을 항상 include해야 합니다.
표준 입출력 라이브러리에 대해선 이 포스트 를 참고하세요.
Time Values
역사적으로 UNIX 시스템은 두 가지 다른 시간 값을 써왔습니다. 그 두가지는 달력 시간과 프로세스 시간인데, 각각 살펴보겠습니다.
Calendar time
이 값은 1970년 1월 1일(UTC)으로부터 몇 초가 지났는지에 대한 값입니다.
이 값은 파일이 마지막으로 수정된 시간같은 항목에서 쓰입니다.
원시 시스템 데이터 타입 time_t가 이 시간 값을 사용합니다.
Process time
CPU Time이라고도 부르는 프로세스 시간은 프로세스가 사용한 CPU 리소스 점유 시간을 측정한 것입니다.
프로세스 시간은 클락 틱(clock tick) 단위로 측정되고, 보통 초당 50, 60 또는 100틱 정도의 시간입니다.
원시 시스템 데이터 타입 clock_t가 이 시간 값을 사용합니다.
프로세스의 실행 시간을 측정할 때는, UNIX 시스템은 세가지 값을 확인합니다.
Clock time- 프로세스가 실행된 전체 시간입니다.
- 구체적인 값은 시스템에서 실행되고 있는 다른 프로세스의 수에 영향을 받습니다.
User CPU time- 사용자 명령에 소비된 CPU 시간입니다.
- 예를 들어, 프로그램 안에서 1을 더하는 반복문 연산 10번이 있다면 그런 명령을 실행한 시간이 더해집니다.
System CPU time- 프로세스 요청에 의해 커널이 소비한 CPU 시간입니다.
- 예를 들어,
read나write같은 시스템 서비스를 실행하면 커널이 이 서비스를 실행한 시간이 더해집니다.
User CPU time과 System CPU time을 더한 값을 CPU time이라고 부릅니다.
이 포스트 에서 프로세스를 실행할 때의 세 가지 시간 값에 대해 더 자세히 보고, 전체적인 시간과 날짜에 대한 주제는 이 포스트 에서 다루겠습니다.
Finish
다음 포스트에서 이번 포스트에서 다루지 못한 나머지 UNIX 특성을 대략적으로 다뤄보도록 하겠습니다. UNIX_Programming 포스트 시리즈는 각 주제에 대해 더 자세히 다루는 포스팅이 계속 있을 예정입니다.